
Sage 300
L'installation des Modèles vous fournit un ensemble de Vues, de Tableaux de Bord et de Rapports prêts à l'emploi.
L'installation (en supposant que le Central Point soit fraîchement installé et vide), se fera en deux étapes :
- Configuration des Sources de Données pour les bases de données ERP et Entrepôt de Données (facultatif).
- Importation des modèles dans le point central.
Il peut y avoir d'autres étapes, y compris la construction et le chargement des Cubes OLAP.
SEI DataSync
DataSync est nécessaire pour Sage 300 uniquement si vous souhaitez consolider les données dans une base de données afin que les Rapports provenant de différentes Sociétés puissent être consultés dans la même base de données.
Il est également recommandé de le faire si vous ne souhaitez pas interroger la base de données ERP qui utilise les Données de Production, et que vous préférez interroger la copie de cette base de données.
Prérequis
- Une version de Sage 300 prise en charge par Sage
- Une base de données de destination (de préférence, dans la même collation que votre base de données Sage 300 )
- Une version valide du DataSync (voir Installer DataSync pour plus d'informations)
Paramétrer les Connexions
Chaque base de données que vous souhaitez consolider nécessite sa propre connexion Source.
- Peu importe le nombre de Sources dont vous disposez, vous n'avez besoin que d'une seule connexion de Destination.
- Le Fuseau horaire doit être réglé sur GMT lors de la sélection d'un Type de Suivi par Date.
- Suivez la procédure décrite dans Ajouter une connexion source et une connexion de destination pour créer une connexion Source et une connexion de Destination.
Vous devriez obtenir un résultat similaire à ceci pour la connexion Source :
Vous devriez obtenir un résultat similaire à ceci pour la connexion de Destination :
Importer les Extractions
Cette fonction vous permet d'importer un modèle prédéfini ou de restaurer une sauvegarde que vous avez effectuée vous-même avec la fonction Exporter (voir Exporter une Extraction pour plus de détails).
Certains modèles prédéfinis sont déjà disponibles ; si vous n'y avez pas accès, veuillez contacter votre partenaire. Un exemple de modèle prédéfini que vous pourriez utiliser est celui qui définit la liste des tables et des champs à synchroniser pour envoyer des données Sage 300, X3, Acumatica, Salesforce vers le Cloud.
Une extraction par connexion source créée est nécessaire pour récupérer correctement les données.
-
Cliquez sur l'une des extractions de la liste puis sur l'icône Importer une extraction située dans le coin supérieur droit.

- Dans la fenêtre Importer une Extraction, cliquez sur l'hyperlien Choisissez un fichier zip pour naviguer jusqu'à l'emplacement où vous avez enregistré le fichier d'exportation.zip ou faites-le glisser directement dans cette fenêtre et cliquez sur Suivant.

Pour Sage 300, deux fichiers zip seront fournis.
- If you are doing a consolidation, import the DS_EXTR_[Software-Version]_[Extraction-Version]_Sage 300 with refresh DS-CONSO.zip file.
- Si vous n'avez qu'une seule Compagnie et que vous souhaitez reproduire la base de données, importez le fichier DS_EXTR_[Version-Logiciel]_[Version-Extraction]_Sage 300 with refresh DS-SYNC.zip pour effectuer une synchronisation.
-
Dans le volet de gauche, sélectionnez le type d'extraction que vous souhaitez effectuer et cliquez sur Suivant.


Si vous effectuez une consolidation, assurez-vous d'avoir le même Nom de Colonne pour le champ Identifiant Unique.
Bien qu'il n'y ait pas de restriction pour Sage 300, il est recommandé d'utiliser CPYID pour le Nom de Colonne et les codes de la Société pour le champ Unique Identifier.
-
Référez-vous à Configurer le panneau d'extraction pour définir l'extraction et cliquez sur Importer pour terminer le processus.


- Vous devriez obtenir un résultat similaire à celui-ci :

Le schéma ci-dessous illustre comment Guide Utilisateur traite les données.

La fenêtre Extractions passera automatiquement à la fenêtre Tables.
Référez-vous Ajouter une requête SQL si vous souhaitez ajouter des instructions SQL à certaines tables et Configurer les champs de table pour personnaliser les champs (ajouter un calcul, changer le nom de la destination, etc.)
Valider et Construire les Extractions
Une fois que votre extraction (source, connexion de destination et leurs tables associées) est configurée, l'étape suivante consiste à valider le paramétrage d'une extraction, avant de pouvoir l'exécuter.
La fonction :
- S'assurera que toutes les tables, les champs et les index existent bien dans les connexions sources;
- Validera toutes les requêtes SQL ou les champs calculés;
- S'assurera que l'intégrité des données dans la connexion de destination n'est pas affectée (ex : modification de la structure de la table).
Pour valider et construire un extraction :
-
Sélectionnez l'extraction que vous souhaitez valider et construire dans la liste et cliquez sur l'icône Valider et Construire.

-
Dans la boîte de dialogue, effectuez une des actions suivantes.
-
Pour les extractions de type Synchronisation et Consolidation, choisissez une des options suivantes et cliquez sur Construire:

-
Traiter uniquement les tables pour lesquelles la configuration a changé depuis la dernière validation : Cette option est sélectionnée par défaut. Elle ne va modifier que les objets qui ont changé.
-
Ajouter seulement les Tables/Champs/Index manquants : Sélectionnez cette option pour appliquer seulement les changements (ajouts, mises à jour et suppressions). La structure sera mise à jour et les données existantes seront conservées pour les objets qui ont changé.
Pour appliquer les modifications à tous les objets, sélectionnez cette option et enlevez la première option.
-
Supprimer l'objet précédemment créé et recréer les objets... : Sélectionnez cette option pour supprimer et recréer les objets qui ont changé depuis la dernière validation.
Pour recréer tous les objets, sélectionnez cette option et enlevez la première option.
-
-
Pour les extractions de type Migration et Exportation, cliquez sur Valider.

-
-
Attendez que le processus soit terminé. Une fenêtre Rapport de Validation apparaîtra pour vous donner un bref aperçu du processus une fois qu'il sera terminé. Les résultats sont affichés dans la colonne Statut. S'il y a une erreur, cliquez sur l'hyperlien dans la colonne Erreur pour voir les détails dans la page des journaux.



Lancer les Extractions
Une fois vos données validées (voir Valider et Construire une Extraction pour plus de détails), vous pouvez lancer manuellement l'extraction si vous voulez un résultat immédiat au lieu de la planifier.
-
Sélectionnez l'extraction que vous souhaitez exécuter dans la liste et cliquez sur l'icône Lancer l'Extraction Maintenant.

-
Dans le coin supérieur droit, choisissez l'action que vous voulez exécuter et le(s) table(s) puis cliquez sur Exécuter.
-
Charger (uniquement pour une extraction de type Migration) : Charge toutes les données de votre destination à partir de votre source.
-
Tronquer et Charger : Remplace toutes les données de votre destination par les données actuelles de votre source.
-
Charge Incrémentale : Récupère uniquement les enregistrements qui ont changé depuis votre dernière Charge Incrémentale et remplacez les enregistrements correspondants dans votre destination par ceux qui ont été mis à jour.
-
Traitement des Enregistrements Supprimés : Nombre maximal de jours pendant lesquels le processus de validation vérifie si des enregistrements ont été supprimés en fonction de la date de la dernière modification. Par exemple, si la valeur est définie à 30 jours, le système vérifiera toutes les transactions qui ont été créées ou mises à jour au cours des 30 derniers jours et validera ensuite si elles existent toujours dans la source. Si elles n'existent plus dans la source, elles seront alors supprimées de la destination.
Exemple
-
-
Attendez que le processus soit terminé. Lorsque le processus est terminé, les résultats sont affichés dans la colonne Statut. En cas d'erreur, vous pouvez obtenir plus de détails en cliquant sur l'hyperlien dans la colonne Erreur, qui mène à la page des journaux.


Configuration de la Sources de Données
Environnements et sources de données
La description donnée à une Source de Données créée pour la première fois est utilisée dans tous les environnements pour décrire cette Source de Données.
Donnez une description générique pour la première fois (par exemple, ERP Data Source, Cube Data Source) et si nécessaire, renommez-la après la création du premier environnement.
Les informations suivantes sont nécessaires pour configurer les Sources de Données :
- Identifiants du serveur de base de données :Nom du serveur, Instance, Stratégie d'authentification.
- Principales informations de la base de données ERP :Nom de la base de données et du schéma.
Source des données ERP
-
Dans le coin supérieur droit, cliquez sur le bouton
 pour accéder à la section Administration.
pour accéder à la section Administration.
- Dans le volet de gauche, sélectionnez Env. & Sources de Données.
-
Par défaut, il existe déjà un environnement appelé Production, que vous pouvez renommer en double-cliquant dans la zone de texte. Une fois la modification effectuée, appuyez sur la touche Entrée.

-
Dans la section Sources de données, cliquez sur
 Ajouter pour créer la première source de données.
Ajouter pour créer la première source de données.
- Terminer la configuration de la source de données ERP. Voir les instructions pour MS SQL Server ci-dessous.




- Description de la source de données :
- Sage 300 Data Source
- Type :
- SQLSERVER
- Serveur :
- Database server of Sage 300
- Nom de la base de données :
- Nom de la Sage 300base de données de synchronisation (attention à la casse)
- Nom du schéma de base de données :
- Créez les deux entrées suivantes en cliquant sur l'icône (remplacez DatabaseName par la valeur appropriée) :
- DatabaseName.dbo
- DatabaseName.SEI_CUSTOM_SCHEMA
NoteThis second line contains the SEI Custom Schema.
Vous pouvez en utiliser un autre, mais nous vous recommandons fortement de suivre cette convention d'appellation :
- Start with SEI
- Utilisez des majuscules
- Separate words by an underscore
NoteThe application searches for tables in the same order as the schemas are listed. Dès qu'une table est trouvée dans un schéma quelconque, l'application arrête la recherche. Par conséquent, si vous avez plusieurs tables portant le même nom dans différents schémas, veillez à ce que le schéma contenant la table que vous souhaitez utiliser apparaisse en premier.
ImportantChoose a unique Custom Schema name for each Environment.
- SEIschéma :
- Saisissez le schéma SEIpersonnalisé choisi pour l'environnement actuel.
- Stratégie d'authentification :
- UseSpecific
- Nom d'utilisateur :
- SQL User accessing the Sage 300 database. Par exemple, sa.
- Mot de passe :
- Le mot de passe de l'utilisateur.
- Cliquez sur Valider puis sur Enregistrer pour terminer la configuration de la source de données.
Source de Données du Cube
Seulement si vous installez le modèle UDM par la suite.
Dans le même Environnement que la Source de Données ERP, créez une nouvelle Source de Données pour le Cube OLAP.
Complétez la définition de la source de données avec toutes les informations appropriées.
The image below provides an example of this.

- Serveur :
- Serveur de base de données sur lequel est installé le paquet d'installation SEI OLAP For SQL Server.
- Nom de la base de données :
- SEICube.
- Nom du schéma de base de données :
- SEICube.SEI_FOLDER (replace FOLDER by the folder name).
- Where SEI_FOLDER (replace FOLDER by the folder name) is the schema used in the ERP Database of the same environment.
- SEIschéma :
- Saisissez le schéma personnalisé choisi pour l'environnement actuel.
- Cliquez sur Valider puis sur Enregistrer.
- Cliquez sur Définir comme entrepôt de données pour définir la source de données comme entrepôt de données, puis entrez les informations suivantes :
- Schéma d'entrepôt de base de données :
- Saisissez à nouveau le schéma SEI personnalisé que vous avez choisi.
- Utilisez MARS pendant le chargement des cubes :
- Non contrôlé
- Cliquez sur Valider puis sur Enregistrer.
Reportez-vous à Environments and Data Sources pour plus de détails sur l'option MARS.
Importer des Modèles
Pour chaque environnement, les informations suivantes, précédemment configurées, seront requises :
- Nom de la base de données ERP
- SEI Schéma personnalisé
- Schéma ERP
Téléchargez le fichier du modèle : TPL_Major.Minor.Build_Sage300.zip.
Le X représente le numéro de construction du modèle (utilisez le plus haut disponible).
Démarrer l'importation d'un modèle
-
Dans le coin supérieur droit, cliquez sur
pour accéder à la section Administration.
- Dans la section Administration, cliquez sur le menu déroulant
 Modèles dans le volet de gauche.
Modèles dans le volet de gauche. - Sélectionnez
 Importer un modèle.
Importer un modèle. -
Choisissez l'emplacement spécifique où les nouveaux modèles seront installés et cliquez sur Suivant.
 Note
NoteHabituellement, le dossier Racine est utilisé.

-
Dans la fenêtre Importer un Modèle, cliquez sur Sélectionner les fichiers...

- Trouvez le dossier où vous avez enregistré le fichier Template.zip afin de le sélectionner puis cliquez sur Ouvrir.
- Dans l'écran Mappage des sources de données, associez les Sources de données (ERP) listées dans la colonne Description des sources de données reçues (celles du modèle) aux sources de données que vous avez définies précédemment dans le Central Point (listées dans la colonne Description des sources de données actuelles).
- Dans la colonne Description des sources de données reçues, assurez-vous que seules les cases Sources de Données que vous souhaitez utiliser à partir du modèle sont cochées.
- Dans la colonne Description des sources de données actuelles, cliquez sur Lier une source de données pour accéder à la liste déroulante contenant les sources de données existantes et cliquez sur Suivant.

Dans l'écran suivant, l'intégralité du contenu des modèles est affichée, par rapport à ce que le Central Point utilise déjà.
Par défaut, lors de la première installation, tout sera défini sur Ajouter (laisser tel quel).
- Dans le cas d'une première installation, les quatre premières colonnes afficheront Aucune et Jamais installé, les trois suivantes détailleront le contenu du modèle, et les trois dernières vous donneront le choix d' Ajouter, Mettre à jour ou Sauter pendant l'installation.Note
Dans le cas d'une mise à jour, vous pouvez vous référer à Mettre à jour un modèle pour plus de détails.
- Cliquez sur Suivant (cela peut prendre du temps).


- Une fois cette opération terminée, une fenêtre vous demandera d'entrer les paramètres nécessaires à la création des objets personnalisés.
- Si plus d'un environnement a été créé, vous verrez une colonne par environnement. Vous pouvez décocher une case Environnement, auquel cas les Scripts Globaux ne s'exécuteront pas.
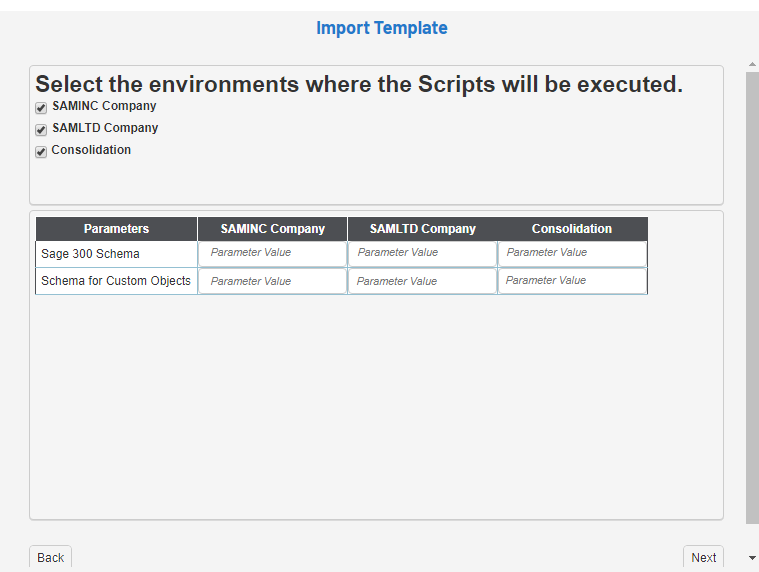
-
Complétez les paramètres, voir les exemples ci-dessous, et cliquez sur Suivant.


- Après l'importation, un Rapport d'Exécution sera produit, comme indiqué ci-dessous.Note
La première section concerne la Source de Données ERP et la suivante la Source de Données Cube.
Vous pouvez cliquer sur le bouton
 pour voir les détails de chaque script individuellement. Si aucune panne n'est signalée, fermez la fenêtre.
pour voir les détails de chaque script individuellement. Si aucune panne n'est signalée, fermez la fenêtre.

- Si l'un des scripts ne s'exécute pas, une icône d'échec
 s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtre Aperçu du Rapport, qui affiche le script SQL correspondant.
s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtre Aperçu du Rapport, qui affiche le script SQL correspondant.
- Copiez ce script, déboguez, et exécutez le séparément si nécessaire. Les utilisateurs qui maîtrisent SQL peuvent le déboguer directement dans la fenêtre Aperçu du Rapport et l'exécuter en cliquant sur le bouton Essayer de le ré-exécuter.


Mettre à jour un modèle
Quelques considérations dont vous devez tenir compte avant de commencer :
- Faire de nouvelles sauvegardes de la base de données SEI et du Central Point est fortement recommandé avant de faire la mise à jour du modèle.
- Vérifier les Modèles de Données de SEI et les Objets SQL Personnalisés de SEI qui peuvent avoir été livrés avec la version initiale du modèle, car vous pourriez perdre ces personnalisations lors de la mise à jour.
- Vous devez disposer d'une version de modèle correspondant à la version du logiciel installée.
Lors d'une mise à jour du logiciel SEI, seule la version du logiciel est mise à jour, et non le modèle. En d'autres termes, les Modèles de Données et les Vues SEI existants ne seront pas affectés.
Après une mise à jour du logiciel, il n'est pas obligatoire d'effectuer systématiquement une mise à jour du modèle. Une mise à jour du modèle est utile si vous avez rencontré des problèmes avec des modèles de données SEI spécifiques ou des objets SQL personnalisés SEI car elle inclut des correctifs.
Pour mettre à jour un modèle :
-
Après avoir mappé les sources de données, cochez les cases des objets que vous souhaitez mettre à jour et cliquez sur Suivant.
 Note
NotePar défaut, aucune case à cocher dans la colonne Mise à jour ne sera cochée. S'il y a un nouveau Modèle de Données ou une nouvelle Vue, la case Ajouter sera cochée. Sélectionnez Sauter si vous voulez l'ignorer.
ImportantSi vous cochez la case Mettre à jour, il écrasera les objets SEI existants associés à ce modèle de données ou connectés aux autres (dépendances). Veuillez noter que si des personnalisations ont été faites, elles seront perdues.

- Sélectionnez l'environnement dans lequel les scripts seront exécutés et cliquez sur Suivant.
- Complétez les paramètres et cliquez sur Suivant.
- Dans la fenêtre Rapport d'exécution, si l'un des scripts ne s'exécute pas, une icône d'échec s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtreAperçu du Rapport, qui affiche le script SQL correspondant.
-
Copiez ce script, déboguez, et exécutez le séparément si nécessaire. Les utilisateurs qui maîtrisent SQL peuvent le déboguer directement dans la fenêtre Aperçu du Rapport et l'exécuter en cliquant sur le bouton Essayer de le ré-exécuter.
Les Navigateurs Web ont mis à jour leur politique concernant les Cookies et ces changements doivent être appliqués à votre Client Web si vous souhaitez intégrer SEI à votre site ERP, ou utiliser l'Authentification Unique (SSO). Reportez-vous à Gestion des Cookies pour plus de détails.
Configurer les Champs Optionnels
Optional Fields is a feature of Sage 300 that has been imported into SEI.
For Sage 300, there are seven types of configurable Optional Fields:
| Global Variable | Sage 300 Table | Number of Variables |
| @@GLOPT | Account | 5 |
| @@ICITEMOPT | Item | 9 |
| @@ORDOPT | Order | 5 |
| @@CUSOPT | Customer | 9 |
| @@GLPOSTO | Posted Transaction | 5 |
| @@VENDOPT | Vendor | 10 |
To access the various Optional Fields available in Sage 300, you must first configure them using the Global Variables available in the template.
Optional Field ETL
The optional field ETL refers to new logic that improves analysis of optional fields and lets users create custom data models that are perfectly tailored to their own specific needs. In the past, all optional fields were considered strings which sometimes made analysis impossible without performing additional steps (e.g., adding aggregations to measures). It also lengthened the data model creation process, since joins had to be granted access to optional fields.
However, with the optional field ETL, Sage 300 uses the data type that was defined by the user in their ERP when creating tables and views. Users can also use the feature to pivot optional field tables to make all of their data accessible from one object.
If you are using DataSync, please make sure that your primary keys are well defined. If no changes were made, the application will add your primary keys by default.
The optional field ETL uses your primary keys to determine which fields are required for Joins on fact tables. If no primary key can be found, it will use your Clustered Index instead.
Process
To perform an optional field ETL operation:
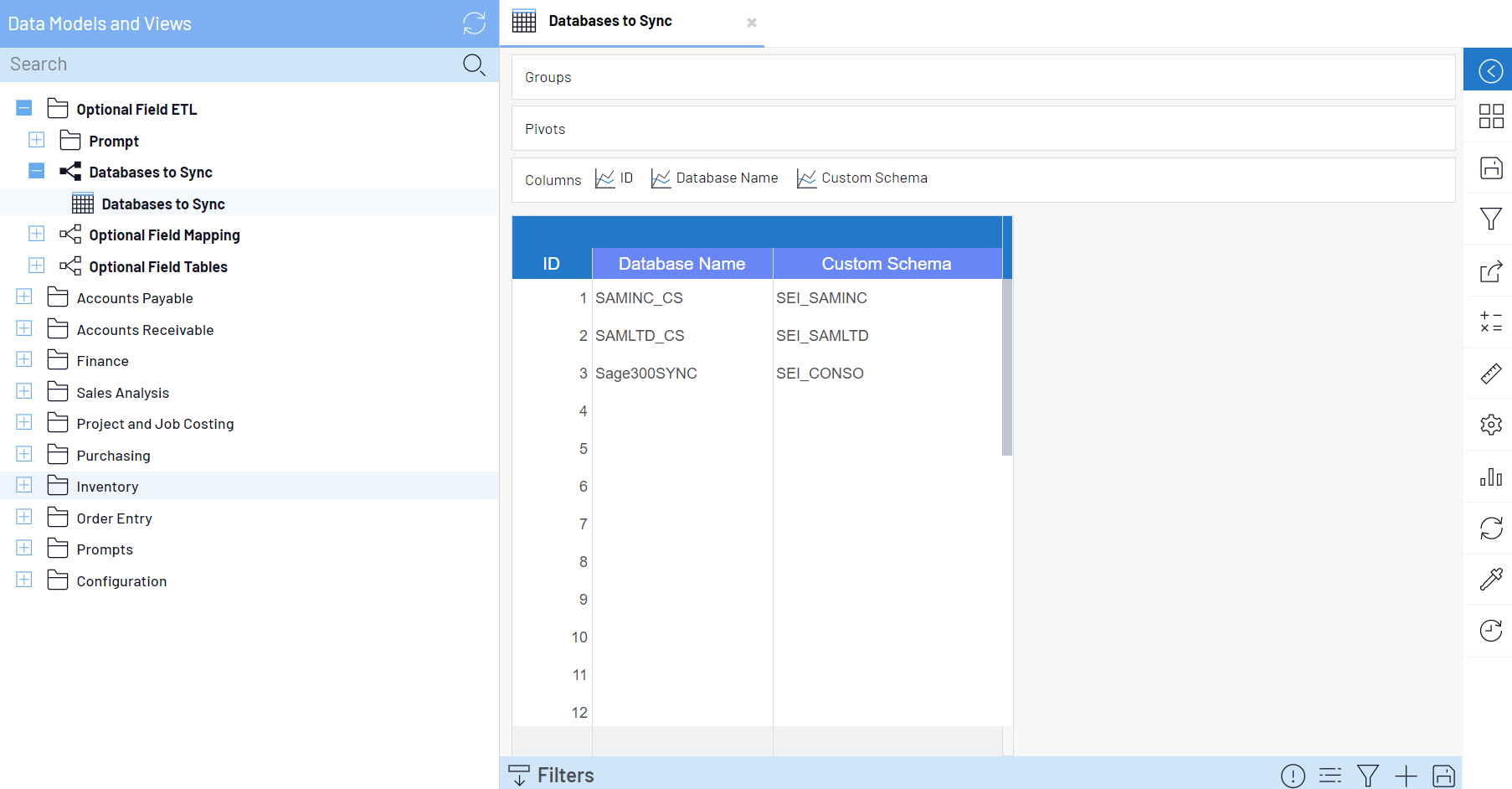
- Find Databases to Sync under Data Models and Views and open the worksheet inside of it (also called Databases to Sync). Add all databases and custom schemas from all of your environments to the worksheet. Doing so will ensure that your ETL object has the same definition across all your environments and will prevent potential data model issues when changing environments.
- Now, find Optional Field ETL under Data Models and Views then right-click on Optional Field Tables and select View Info Page. Now, run the Update Table List info page (shown below) to scan through your -O tables (e.g., ARCUSO for Customer Optional Fields) and retrieve any optional fields contained therein. The info page will refer to your CSOPTH table for the new data type value.
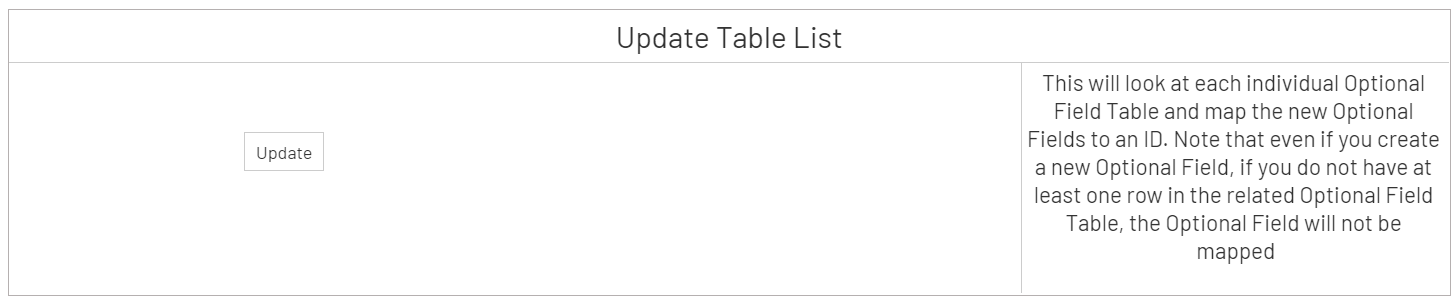
Please note that if you previously consolidated multiple databases and the same optional field exists in more than one database, the Update Table List info page will retrieve the most recent definition based on audit date and time.
- Locate and open the Tables included in Refresh All worksheet (shown below). This worksheet contains all optional field tables and allows you to choose whether the ETL will produce a view or a table.
Tables allow for faster query operations but do not update in real-time (i.e., orders will not appear in your optional fields until you perform a load).
Views do update in real-time without having to load but have slower query operations.
You can also choose which tables are included in the ETL from the Tables included in Refresh All worksheet. By default, all tables that are currently used by the template will be included in the ETL. To add more tables, simply change the Included in ETL for All Objects value to 1. - After selecting an object type, return to the Optional Field Tables info pages and run ETL for All Objects (shown below). This will create your view or table. If you chose to create a table, the load will be incremental to shorten load time.

Regardless of the object type you selected, the new object will have the same name as the table preceded by the PVT_ prefix. The optional fields will appear as new fields, and the unique keys for Joins can be found in each object.
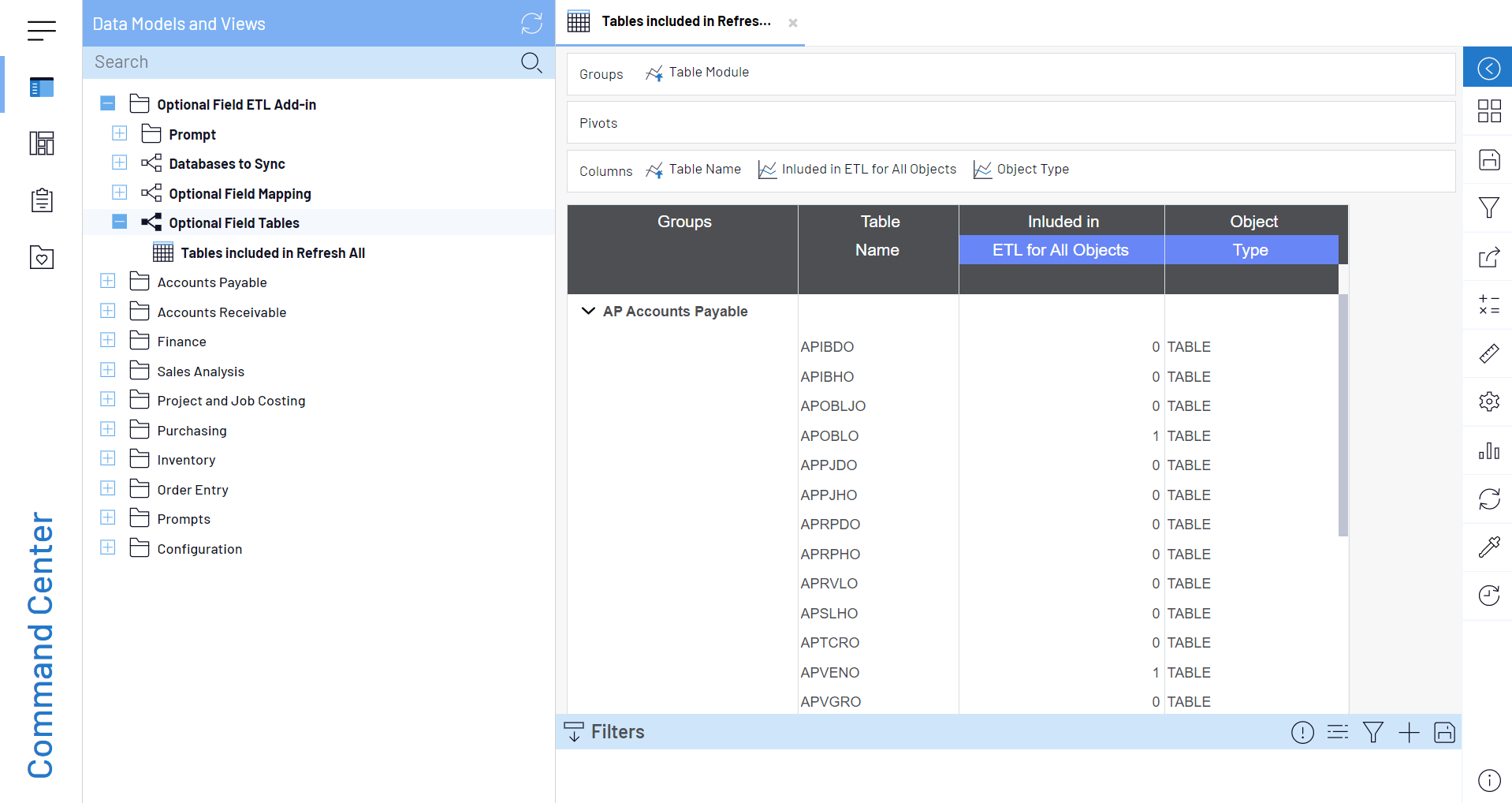

The third Optional Field Tables info page—ETL for Single Table—allows you to run the ETL on a single table and change its flag value to 1.
If you are unable to run this info page on a particular table, try checking the Drop and Recreate flag and then re-running the operation.

- Since optional field names are unique for each user, you must manually add your fields to each data model if you want them to be used in analyses. Please note that you may wish to add Prompts and Global Parameters as well depending on what you wish to do with your fields.