
Fonction supplémentaire
Aperçu
La propriété de la colonne Fonction supplémentaire permet à l'utilisateur d'effectuer des calculs sur un ensemble de lignes du tableau qui sont liées d'une certaine manière à la ligne sélectionnée. Les calculs de la Fonction supplémentaire sont similaires aux calculs de la Fonction d'agrégation, mais avec la distinction unique qu'ils ne provoquent pas le regroupement des lignes calculées en une seule ligne de sortie. Toutes les lignes impliquées dans un calcul de la Fonction supplémentaire conservent leur identité distincte.
La Fonction supplémentaire est uniquement compatible avec les sources de données de type MS SQL ou Oracle.
Configuration
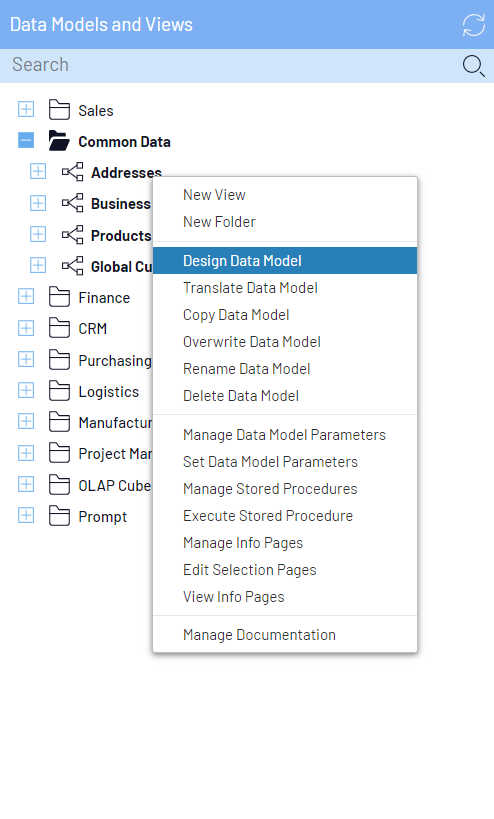
Pour effectuer un calcul de la Fonction supplémentaire, l'utilisateur doit d'abord se rendre dans le Concepteur de modèle de données en cliquant avec le bouton droit de la souris sur une entrée de Modèle de données et en sélectionnant Concepteur de modèle de données (comme illustré ci-dessous).
Vous pouvez trouver la ligne Fonction supplémentaire dans l'onglet Général du Concepteur de modèle de données. Comme pour les autres propriétés de colonnes, si vous cliquez sur la case à cocher qui apparaît après avoir cliqué sur une cellule de la ligne Fonction supplémentaire, une fenêtre contextuelle s'affiche et vous permettra de configurer votre calcul (voir ci-dessous).
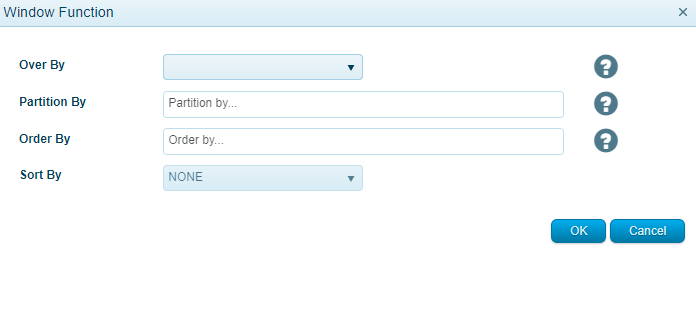
La fenêtre contextuelle Fonction supplémentaire contient les 4 champs déroulants suivants :
- Over By - Définit le type de calcul de la fonction supplémentaire (Paramètre obligatoire)
- Partition By - Définit les dimensions par lesquelles l'ensemble de résultats de la requête est divisé en partitions (Paramètre facultatif)
- Order By - Définit l'ordre dans lequel l'ensemble des résultats de la requête sera organisé (Paramètre obligatoire)
- Sort By - Définit l'ordre de tri du calcul, c'est-à-dire ASC, DESC ou NONE (Paramètre facultatif)
Le Sous-total de la colonne doit avoir une valeur autre que Aucun (par exemple, Somme, Min, Max, Count, etc.) Si la valeur du Sous-total de la colonne est Aucun, la Fonction supplémentaire ne pourra pas être appliquée.
Occasionnellement, SEI exige un chargement forcé de toutes les données de la vue (y compris les données à la demande) lors de l'application d'une Fonction supplémentaire. Ceci est dû au fait que la valeur sélectionnée dans le champ Partition By n'est pas au même niveau que la vue.
Valeurs de la clause Over By
Fonctions supplémentaires d'agrégation
- SUM - La fonction supplémentaire SUM() calcule la somme de toutes les valeurs saisies dans l'expression. Cette fonction ne peut être appliquée qu'à des valeurs numériques et elle ignore les valeurs NULL.
- AVG - La fonction supplémentaire AVG calcule la moyenne de toutes les valeurs saisies dans l'expression. Cette fonction ne peut être appliquée qu'à des valeurs numériques et elle ignore les valeurs NULL.
- COUNT - La fonction supplémentaire COUNT() calcule le nombre total de lignes d'entrée.
- COUNT(*) calcule le nombre total de lignes dans la table cible, incluant ou non des valeurs NULL.
- COUNT(expression) calcule le nombre de lignes qui ont des valeurs autres que NULL dans une colonne ou expression spécifique.
- MIN - La fonction supplémentaire MIN() calcule la valeur minimale de toutes les valeurs saisies dans l'expression. Cette fonction ne peut être appliquée qu'à des valeurs numériques et elle ignore les valeurs NULL.
- MAX - La fonction supplémentaire MAX() calcule la valeur maximale de toutes les valeurs saisies dans l'expression. Cette fonction ne peut être appliquée qu'à des valeurs numériques et elle ignore les valeurs NULL.
Fonctions supplémentaires de classement
-
CUME_DIST - La fonction supplémentaire CUME_DIST() calcule le rang relatif de la ligne actuelle à l'intérieur d'une partition de fenêtre (c'est-à-dire le nombre de lignes qui précèdent ou qui sont au même niveau que la ligne actuelle / le nombre total de lignes dans la partition de fenêtre).
-
DENSE_RANK - La fonction supplémentaire DENSE_RANK() calcule le rang d'une valeur dans un groupe de valeurs en fonction de l'expression Order By et de la clause OVER. Veuillez noter que les valeurs ne sont classées qu'à l'intérieur de leur partition, que les lignes ayant des valeurs égales sont attribuées le même rang et qu'il n'y a aucun intervalle dans la séquence des valeurs classées si deux lignes ou plus ont le même rang.
-
NTILE_4 / NTILE_100 - La fonction supplémentaire NTILE divise les lignes de chaque partition de fenêtre, aussi uniformément que possible, en un nombre spécifié de groupes classés (c'est-à-dire 4 ou 100). Cette fonction nécessite une clause Order By dans la clause OVER.
-
PERCENT_RANK - La fonction supplémentaire PERCENT_RANK() calcule le rang en pourcentage de la ligne actuelle en utilisant la formule suivante : (x - 1) / (le nombre de lignes dans la fenêtre)
-
RANK - La fonction supplémentaire RANK calcule le rang d'une valeur à l'intérieur d'un groupe de valeurs. L'expression Order By de la clause OVER détermine la valeur classée, et chaque valeur est classée dans sa partition. Toutes les lignes de valeur égale selon les critères de classement se voient attribuer le même rang. Détails de formule ajoute le nombre de lignes liées au rang lié afin de calculer le rang suivant. Pour cette raison, les rangs ne peuvent pas être des chiffres consécutifs.
-
DENSE_RANK - La fonction supplémentaire DENSE_RANK fonctionne exactement comme la fonction supplémentaire RANK mais diffère en ce qu'il n'y aura pas d'écart si deux lignes ou plus sont liées.
-
ROW_NUMBER - La fonction supplémentaire ROW_NUMBER calcule le nombre ordinal des lignes actuelles dans une partition. Le nombre est déterminé par l'expression Order By dans la clause OVER. Chaque valeur est ordonnée à l'intérieur de sa partition et les lignes de valeur égale, selon l'expression Order By, se voient attribuer des numéros de ligne différents de manière non déterministe.
Fonctions supplémentaires de valeur
-
LAG - La fonction supplémentaire LAG() renvoie la valeur de la ligne précédant la ligne actuelle dans la partition. Si aucune ligne avant la ligne actuelle n'existe dans la partition, une valeur NULL est retournée.
-
LEAD - La fonction supplémentaire LEAD() renvoie la valeur de la ligne qui suit la ligne actuelle dans la partition. Si aucune ligne après la ligne actuelle n'existe dans la partition, une valeur NULL est retournée.
-
FIRST_VALUE - La fonction supplémentaire FIRST_VALUE renvoie la valeur de l'expression spécifiée par rapport à la première ligne qui s'affiche dans la fenêtre.
-
LAST_VALUE - La fonction supplémentaire LAST_VALUE renvoie la valeur de l'expression spécifiée par rapport à la dernière ligne qui s'affiche dans la fenêtre.
Fonctions supplémentaires statistiques
-
STDEV - La fonction supplémentaire STDEV calcule l'écart type statistique de toutes les valeurs dans l'expression spécifiée.
-
STDEVP - La fonction supplémentaire STDEVP calcule l'écart type statistique de la population de toutes les valeurs dans l'expression spécifiée.
-
VAR - La fonction supplémentaire VAR calcule la variance statistique de toutes les valeurs dans l'expression spécifiée.
-
VARP - La fonction supplémentaire VARP calcule la variance statistique de la population de toutes les valeurs dans l'expression spécifiée.
Les fonctions supplémentaires statistiques ci-dessus sont répertoriées par leur nom MS SQL. Si vous utilisez une source de données de type Oracle, ces fonctions seront remplacées par leurs équivalents Oracle (c'est-à-dire STDDEV, STDDEV_POP, VARIANCE et VAR_POP).
Valeurs Partition By
Partition by Dynamic
Si la valeur Dynamic est sélectionnée de la liste déroulante Partition By, l'ensemble de résultats sera automatiquement partitionné par le niveau de la vue. Pour une vue sans pivot, il s'agit généralement du niveau parent.
Partition by Dimension
Si une ou plusieurs dimensions sont sélectionnées de la liste déroulante Partition By, l'ensemble de résultats sera partitionné selon les dimensions choisies.
Valeurs Order By
Order by Current Measure Value
Si vous sélectionnez la valeur Current Measure Value de la liste déroulante Order By, l'ensemble des résultats de la requête sera ordonné par le champ de mesure actuel pour calculer la fonction supplémentaire.
Vous avez 12 lignes et vos données sont regroupées par mois, vous avez donc une ligne par mois. Si vous appliquez une fonction supplémentaire SUM() où la valeur du champ Order By est Current Measure Value, les 12 valeurs mensuelles seront additionnées en ordre de valeur croissante plutôt qu'en ordre séquentiel.
Order by Dimension
Si une ou plusieurs dimensions sont sélectionnées de la liste déroulante Order By, l'ensemble de résultats sera ordonné selon les dimensions choisies.